
Seven Prompts No AI Image Generator Can Get Right
We ran the same 26 adversarial prompts through three AI image generators: Runway Gen4, xAI Grok, and OpenAI GPT, and judged every output with two independent vision models that both had to agree. An image with 12 strawberries instead of 8 scored higher on standard aesthetic metrics than the correct image. That is why we built this evaluation: automated metrics measure beauty, not truth.
Verita AI Research
We ran the same 26 adversarial prompts through three AI image generators: Runway Gen4, xAI Grok, and OpenAI GPT, and judged every output with two independent vision models that both had to agree. An image with 12 strawberries instead of 8 scored higher on standard aesthetic metrics than the correct image. That is why we built this evaluation: automated metrics measure beauty, not truth.
Key findings (26 shared prompts, dual-judge consensus):
OpenAI GPT: 69% (18/26) - strongest on physics, spatial reasoning, and multi-subject scenes
xAI Grok: 65% (17/26) - most accurate on hands (75%) and counting (least bad at 40%)
Runway Gen4: 50% (13/26) - 0% on counting (0/5), weakest overall on precision tasks
Seven prompts defeated all three models - counting, reflections, multi-line text, and pattern regularity are architecturally unsolved
The Challenge
Standard evaluation metrics for image generation don't measure what matters for production use.
FID (Heusel et al., 2017) requires 20,000+ samples, has no compositional understanding, and actively disagrees with human judgment (Jayasumana et al., CVPR 2024). CLIPScore (Hessel et al., 2021) treats text as a bag of words — T2I-CompBench (NeurIPS 2023) confirmed it never ranks among the top metrics for compositional evaluation. Human preference models like HPSv2 and ImageReward predict which image looks better, not which is correct.
Compositional benchmarks have made progress — GenEval (NeurIPS 2023), TIFA (ICCV 2023), DPG-Bench (2024), GenAI-Bench (NeurIPS 2024) — all confirming models struggle with counting, spatial relations, and logical reasoning. But none target specific failure modes adversarially. We designed 26 prompts to break models on purpose — then gave all three the same set.
Our Approach
26 adversarial prompts across 8 dimensions, identical for all three models. Each targets a specific known weakness.
We additionally tested xAI (15 prompts) and OpenAI (20 prompts) on hard-mode dimensions — counting with color constraints, negation, complex text, multi-constraint, and impossible tasks. Runway was not tested on hard-mode prompts. These results are reported separately.
Model | Provider | Shared Prompts | Hard-Mode |
gen4_image_turbo | Runway | 26 | — |
grok-imagine-image-pro | xAI | 26 | +15 |
gpt-image-1 | OpenAI | 26 | +20 |
Dual-judge consensus. GPT-4o + Claude independently evaluate every image. Both must agree on PASS. Built after catching GPT-4o miscounting cherries. Error rate: ~15% single → <5% dual.
Why this matters: We computed CLIP-IQA, Aesthetic Score, Sharpness, and BRISQUE on every image. A Runway image with 12 strawberries instead of 8 scored higher on aesthetic quality than xAI's correct image with 8. A misspelled "XYLOPHONÉ" scored identically to "XYLOPHONE" on every automated metric. Standard metrics cannot distinguish a beautiful wrong image from a beautiful correct one.
Results
1. The Scorecard
All numbers below are computed on the same 26 prompts, evaluated with the same dual-judge system.
Model | Passed | Total | Pass Rate |
OpenAI GPT | 18 | 26 | 69% |
xAI Grok | 17 | 26 | 65% |
Runway Gen4 | 13 | 26 | 50% |
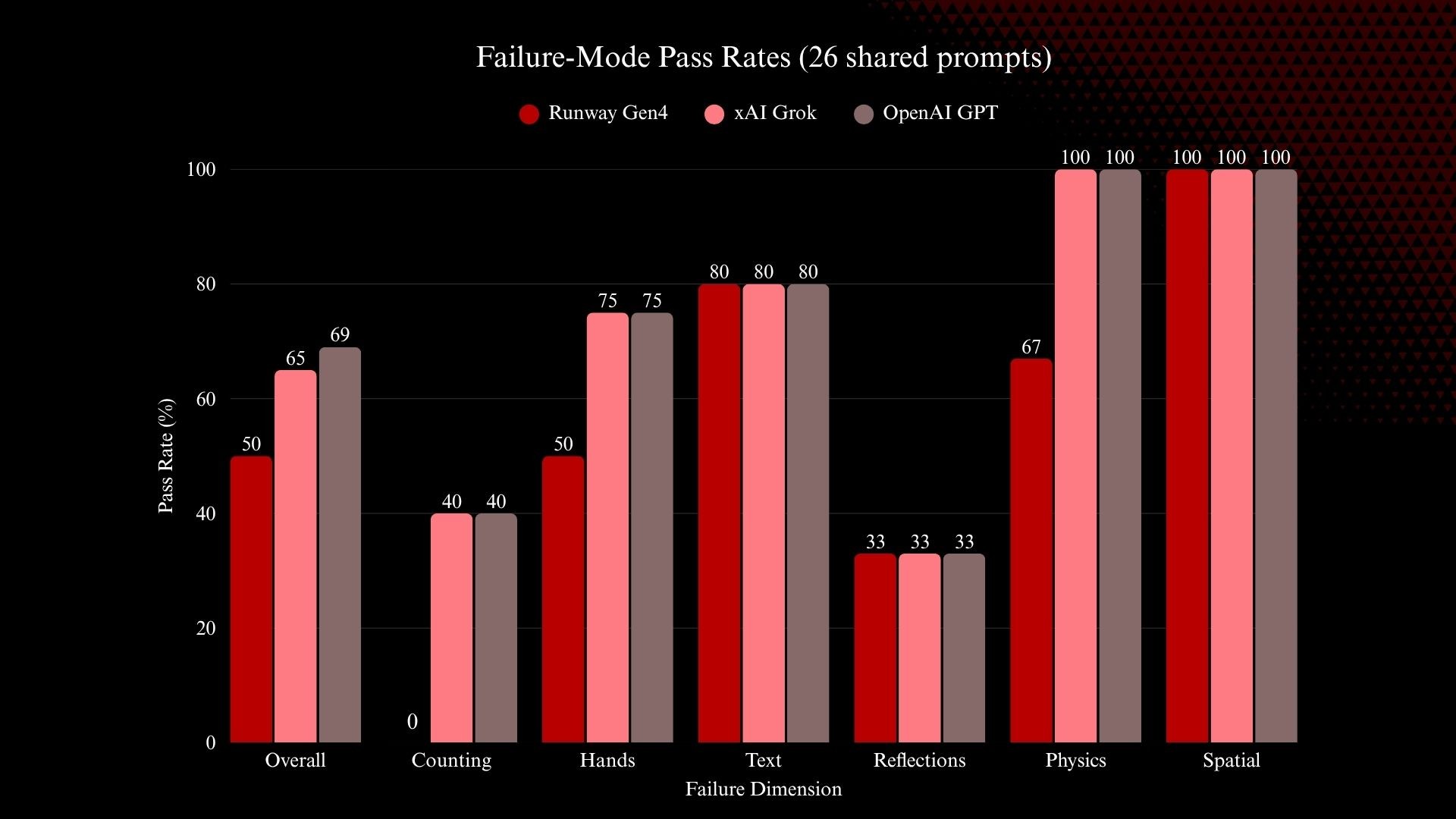
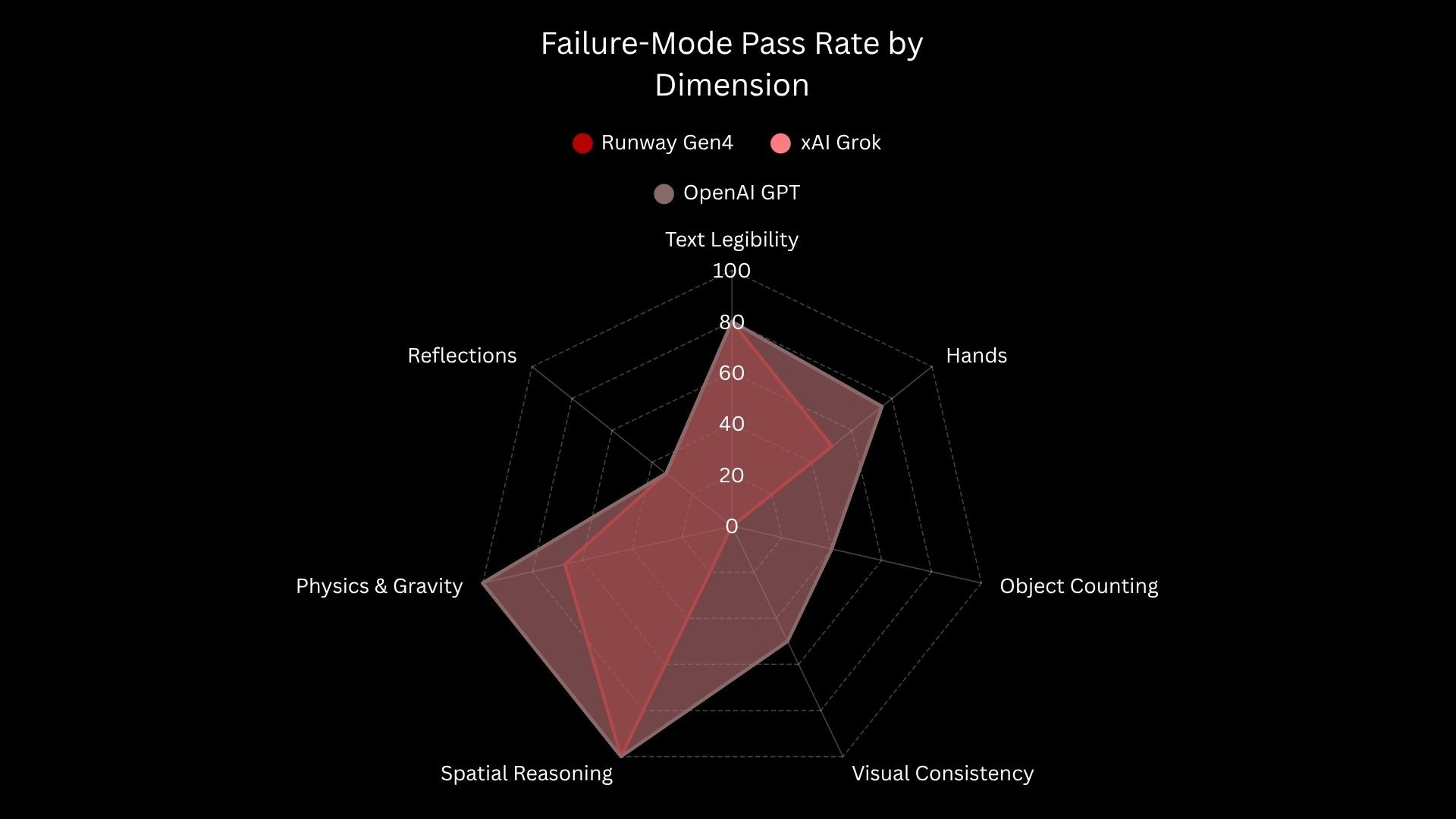
Breaking this down by dimension reveals where each model wins and where the failures concentrate:
Per-dimension breakdown (26 shared prompts)
Dimension | Runway Gen4 | xAI Grok | OpenAI GPT |
Object Counting | 0/5 (0%) | 2/5 (40%) | 2/5 (40%) |
Hands & Fingers | 2/4 (50%) | 3/4 (75%) | 3/4 (75%) |
Text Legibility | 4/5 (80%) | 4/5 (80%) | 4/5 (80%) |
Reflections | 1/3 (33%) | 1/3 (33%) | 1/3 (33%) |
Physics & Gravity | 2/3 (67%) | 3/3 (100%) | 3/3 (100%) |
Spatial Reasoning | 3/3 (100%) | 3/3 (100%) | 3/3 (100%) |
Visual Consistency* | 0/2 (0%) | 1/2 (50%) | 1/2 (50%) |
Multiple Subjects* | 1/1 (100%) | 0/1 (0%) | 1/1 (100%) |
*Small sample sizes (n=1 or n=2) — treat as directional signals, not robust estimates.
Text Legibility: "XYLOPHONE on a classroom sign" — all three pass. 80% accuracy is a genuine 2026 breakthrough compared to ~30% a year ago.
 |  |  |
Runway Gen4 | xAI Grok | OpenAI GPT |
Reflections: "Man raising right hand in mirror" — all three fail. The reflection shows the same hand raised instead of the laterally inverted left hand. 33% across the board.
 |  |  |
Runway Gen4 | xAI Grok | OpenAI GPT |
2. Hard-Mode Results (xAI and OpenAI only)
Runway was not tested on hard-mode prompts. The results below compare xAI (15 additional prompts) and OpenAI (20 additional prompts) on dimensions designed to push multi-constraint reasoning.
Dimension | xAI Grok | OpenAI GPT |
Counting + Attributes | 2/3 (67%) | 1/3 (33%) |
Negation | 2/2 (100%) | 2/2 (100%) |
Complex Text | 2/2 (100%) | 2/3 (67%) |
Multi-Constraint | 0/1 (0%) | 2/2 (100%) |
Logical Consistency | 1/1 (100%) | 1/2 (50%) |
Impossible Task | 0/1 (0%) | 0/1 (0%) |
The multi-constraint dimension is a preliminary signal worth flagging. "A woman in a RED dress holding a BLUE umbrella in front of a YELLOW taxi" — OpenAI got every binding right on both prompts; xAI assigned colors to wrong objects on its single prompt. The sample size is small (n=1 for xAI, n=2 for OpenAI), so this needs a larger test set to confirm, but it hints at a difference in how these models decompose compositional prompts.
Multi-constraint: RED dress + BLUE umbrella + YELLOW taxi — preliminary signal, small sample size
 |  |
xAI Grok FAIL | OpenAI GPT PASS |
3. The Seven Universal Failures
Seven prompts defeated all three models on the shared 26-prompt set:

# | Prompt | Dimension | Why It Fails |
1 | Exactly 11 glass marbles | Counting | Prime numbers; models estimate density |
2 | 3 red, 2 blue, 1 green balloon | Counting | Can't track qty per color |
3 | Exactly 4 pizza slices | Counting | Prototype (6-8) overrides count |
4 | Right hand; mirror shows left | Reflections | Lateral inversion not encoded |
5 | RUNWAY on shirt; YAWNUR in mirror | Reflections | Text + reflection combined |
6 | Menu: LATTE $4.50, MOCHA $5.25 | Text | Multi-line + numbers unsolved |
7 | Correct 8x8 chessboard | Consistency | No global pattern enforcement |
Universal failure #7: "Correct 8x8 chessboard" — all boards look right at a glance; on inspection, same-color squares appear adjacent and alternation breaks across rows.
 |  |  |
Runway Gen4 | xAI Grok | OpenAI GPT |
Universal failure #2: "3 red, 2 blue, 1 green balloon" — models produce roughly equal color distribution instead of the specified 3-2-1 split.
 |  |  |
Runway Gen4 | xAI Grok | OpenAI GPT |
What These Failures Tell Us
The seven universal failures are not random bugs. Each points to a specific architectural limitation — and what would have to change to break through.
Counting fails because diffusion is continuous.
There is no internal mechanism for "exactly 8." Models activate a visual concept and generate approximate quantity by pattern-matching. Consistent failure on prime numbers (11) vs round numbers suggests density estimation, not counting. Breaking this would require a discrete counting module inserted into the generation pipeline.
Reflections fail because geometry isn't encoded.
No architecture represents mirror physics. Reflections are approximate copies, not lateral inversions. This is not a training data problem — mirrors are abundantly represented. It's a representation problem requiring explicit geometric transformation modules.
Pattern regularity fails because generation is local.
The chessboard failure: each local patch may have correct alternation, but there's no enforcement of global consistency across 64 squares. This applies to any repeating pattern — tile grids, brick walls, fabric weaves. Requires constraint propagation that current architectures lack.
Multi-line text fails because rendering is holistic, not sequential.
Single-word text works at 80% because models learn visual word shapes. Multi-line text with numbers requires sequential generation — characters in order, formatting across lines. Current models generate everything simultaneously. Sequential text rendering would require an autoregressive component for text regions.
Is 65-69% a soft ceiling?
xAI and OpenAI cluster at 65-69% on the shared prompts. The remaining 31-35% failures concentrate in architecturally hard dimensions — counting, reflections, pattern consistency. These won't yield to larger training sets. They require structural changes: discrete counting, geometric reasoning, global consistency, sequential text. Until those happen, we may be looking at a capability plateau for prompt-following accuracy.
Conclusion
Use Case | Strongest Model | On This Evaluation |
Counting and hands | xAI Grok | 40% counting, 75% hands (least bad — still failing often) |
Physics and multi-subject | OpenAI GPT | 100% physics, 100% spatial, 100% multi-subject |
Text rendering | All three | 80% across the board — the 2026 success story |
Reflections | None | 33% for everyone — architecturally unsolved |
The seven universal failures require architectural innovation, not more training data: discrete counting modules, geometric reasoning for reflections, global constraint propagation for patterns, and sequential rendering for multi-line text. These are the open problems.
Interested in running these failure-mode prompts on your own models? Reach out to Verita
Appendix
A. Prompt Set and Evaluation Details
The 26 shared prompts were drawn from a larger pool designed to cover known failure modes. xAI was additionally tested on 15 hard-mode prompts; OpenAI on 20. Runway was tested only on the 26 shared prompts.
Judges: GPT-4o (primary) + Claude (secondary). Both must agree. Structured JSON output.
Automated metrics (supplementary): CLIP-IQA, Aesthetic Score (LAION), Sharpness, BRISQUE — not used for pass/fail.
B. Sample: The Strawberry Test
Prompt: "Exactly eight fresh red strawberries in two rows of four on a white ceramic plate."
Model | Count | Verdict |
Runway Gen4 | 12 | FAIL |
xAI Grok | 8 | PASS |
OpenAI GPT | 8 | PASS |
Interested in running these failure-mode prompts on your own models? Reach out to Verita info@verita-ai.com